
背景
Nvida一直从事加速计算芯片的开发,创业初期在当时市场最大的图形芯片GPU上作设计,后续开发了用户可直接操作gpu的CUDA框架,并于2007年开始涉猎自动驾驶的车用芯片研发,而2014年后nvida也因为CUDA在AI模型训练的爆火股价飙升。
NVIDIA DRIVE OS是一个包含了自动驾驶相关的软件驱动、图形计算框架等一系列软件堆栈的合集sdk。由于业务上通信中间件的需求,我将学习其中的DriverWorks的cgf组件。
DriveWorks
DriveWorks SDK 有效利用NVIDIA DRIVE内部的众多处理器平台。并优化硬件引擎之间的数据通信代价,提供许多开箱即用的模块接口。
作为基础平台,提供用于传感器集成、数据记录、图像处理、模块通信等中间件接口。其借助 Compute Graph Framework(CGF)和 System Task Manager(STM)Scheduler 调用各个传感器采集并复现车上数据以实现自动驾驶中间件的功能。 其中DriveWorks ipc采用套接字,需要调用相应api进行DWclient、DWserver的initialize、以及accept、connect、read、write、release,跟tcp通信很像。尝试跑了下案例底层确实如此。组件其他模块暂未了解。

CGF
CGF node类似component,强调数据流的封装融合处理,并由用户来设计数据的处理(data pipeline)即node json与Graphlet json,这两种json可通过ui工具绘制生成。
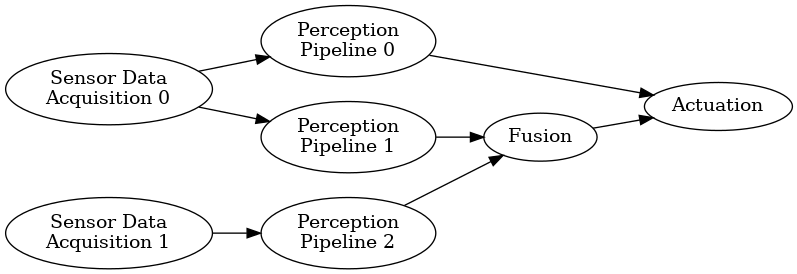
CGF将根据以下文件编译链接生成类似组件动态库so,程序将通过dlopen加载该动态库。自底向上过程如下所示:
设计
.node.json.graphlet.jsonui绘制导出.node.json.graphlet json,通过nodestub指定node生成的相应node、nodeImpl的.h .cc,例如/usr/local/driveworks-5.10/tools/nodestub/nodestub.py --output-path ./mytest /home/general/drive-os/cgf_hello/descriptions/src/HelloNode.node.json 'dw::framework::ExceptionSafeProcessNode'并需用户实现Impl的初始化、注册、处理函数。void initInputPorts(); void initOutputPorts(); void registerPasses(); dwStatus processPass();编辑
.app.json该文件指定其余配置文件路径及stm参数,是启动器launcher入口配置,教程参考文档。(后续nv将提供ui用于生成app.json)其余参数json文件都是可选的,除 sensors.json(传感器布局配置)外皆为stm调度器配置文件:
__standardSchedule.yam- stm调度中间文件,根据app.json 计算生成:
/usr/local/driveworks-5.10/tools/descriptionScheduleYamlGenerator/descriptionScheduleYamlGenerator.py --app my.app.json --output .之后还需对yaml进行修改,添加用户的资源占用等配置(可选)
- stm调度中间文件,根据app.json 计算生成:
__standardSchedule.stm- stm调度器实际加载的各component静态调度文件,如此生成:
/usr/local/driveworks-5.10/tools/stmcompiler -i my__standardSchedule.yaml -o my__standardSchedule.stm
- stm调度器实际加载的各component静态调度文件,如此生成:
wcet.yaml
调度最坏情况执行时间配置文件
编译动态库 一切准备就绪后编辑如下cmake读取app json将相应node生成so。同时cgf提供nodedescriptor等工具来将修改编译后的so导出为node json等文件以下文件进行同步:
.node.json__standardSchedule.stm__standardSchedule.yaml
启动 一般是通过
sudo /usr/local/driveworks/bin/config/run_cgf.sh -p Hello.app.json -s Hello__standardSchedule.stm来启动cgf app、stm等,日志默认放置在LogFolder中。具体流程为启动器bin/launcher解析app.json,并启动调度的stm_master进程与数个 LoaderLite 进程,stm_master类似于进程间消息队列来进行交互,LoaderLite进程将读取相应node json并初始化stm_client与node。
CGF通信channel 类似ros根据通信双方自动选择通信方式,CGF具有共享内存、套接字 IPC 和 NvSciStream (synchronization communication inter-process) 三种。通信数据采用pod(plain-old-data)类型,使用非pod数据类型时除了类型宏声明外还需注册registerPacketConstructor前所述的通信方式,示例参考/usr/local/driveworks/samples/src/dwchannel。
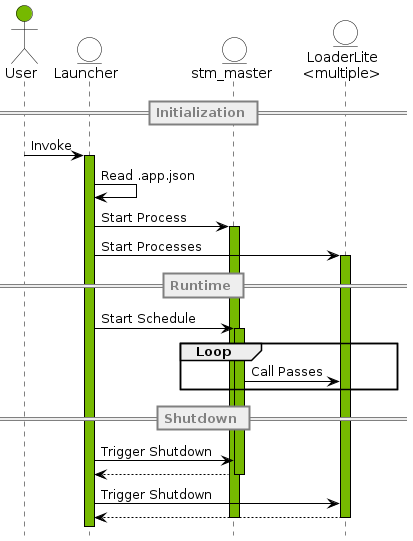
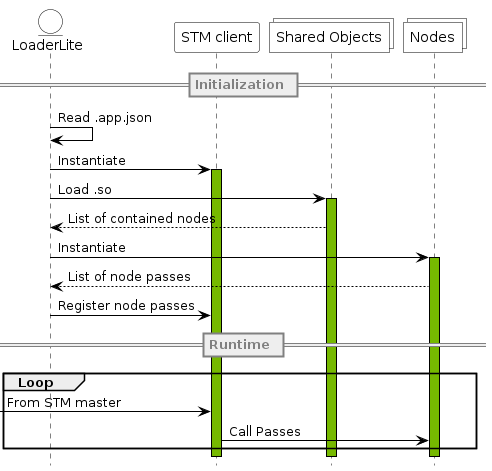
STM
stm解析用户提供的CGF节点yaml配置,来生成静态的的非抢占式调度规则.stm。集中式监控管理Orin上的任务进程。并且可以通过可视化工具显示其调度关系,例如: /usr/local/driveworks/tools/stmvizgraph -i src/cgf/graphs/CGFDemo__slowSchedule.yaml -o output_file3.svg
/usr/local/driveworks/bin/stm_master启动全局STM Master,通过Posix消息队列来与各个STM Client通信,而进程数据帧间的调度将由Schedule Manager进程与master连接进行管理。stm manage生成日志结合 .stm 导入分析工具将生成分析报告。
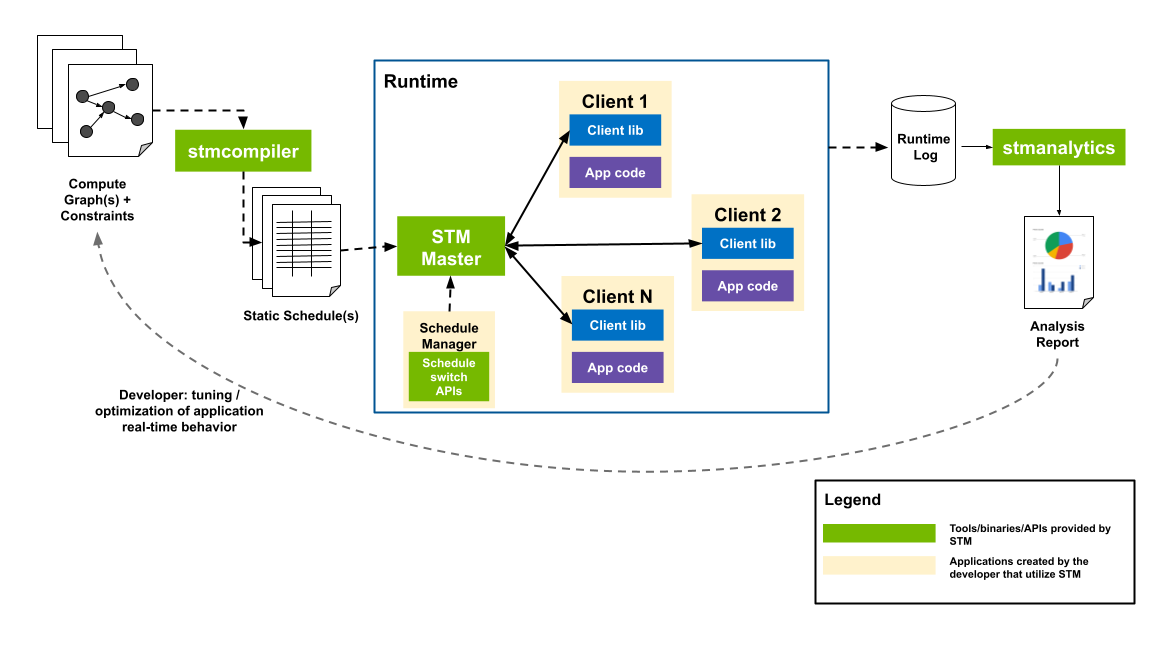
确保仓库正常编译install后,测试stm案例:
/usr/local/driveworks-5.10/tools/stmcompiler \
-i stm_hello/stm_config.yml -o build/stm_hello/stm_config.stm
sudo /usr/local/driveworks/bin/stm_master -s build/stm_hello/stm_config.stm
# new terminal
sudo ./build/stm_hello/stm_hello & sudo ./build/stm_hello/stm_world
CGF时序细节
1. cgf里配置的pass是什么时候被调用
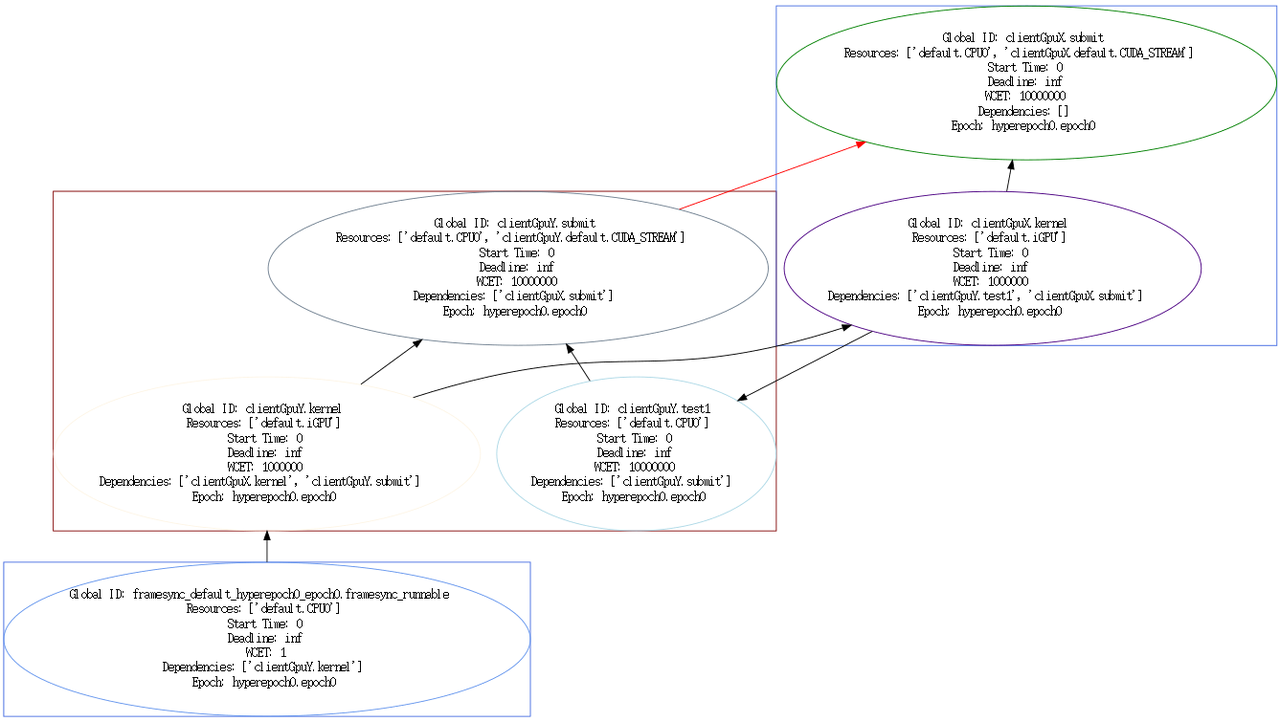
不同于Apollo等通信中间件的消息驱动,driveWorks的cgf node通过stmSchedules设定的时钟周期性的获取消息。需要app.json规划不同的component的周期调用粒度,即配置不同的hyperepochs下的frame帧数与单帧时间period(frame不填默认皆为1)。向下细分,hyperepoch管理一组并行epoch的frame、period,各个epoch在该hyperepoch的单个周期内扫描。如下右图所示,cpu1 cpu2 gpu0(hyperepoch的资源)在同个hyperepoch并行两个周期相差三倍的epoch,其epoch边界彼此同步,而cpu0运行在不同的hyperepoch下。cgf扫描周期图如下。

2. pass内的多个函数之间被调用的顺序以及并发关系
graphlet.json 根据node json派生实例化相应的subcomponents,通过app、graphlet生成静态的调度图standardSchedule.yaml (用户可编辑 其逻辑)并生成.stm文件,之后stm_clientr加载stm作为实际调度规则,每个周期pass的函数调用顺序为逐个遍历runnable子选项(遍历顺序不是按照yaml的顺序)。
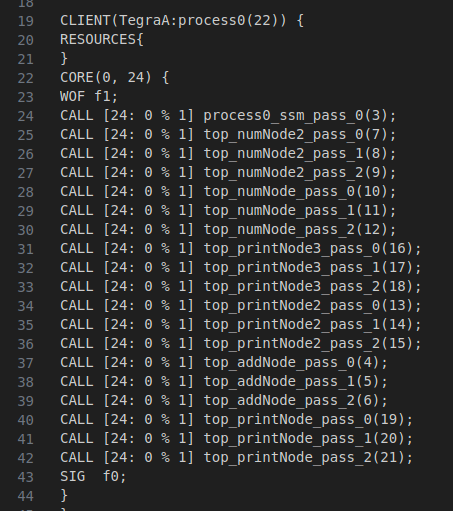
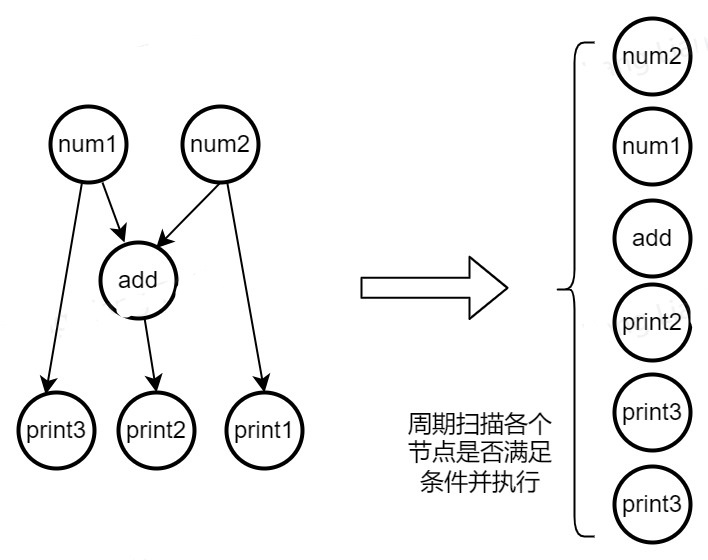
3. cgf节点之间被调用的顺序以及并发关系
DW将单个或数个cgf node整合为一个动态库,其定位类似component动态库。通过app.json配置process*参数来将各类动态库划分在不同soc的不同loadLite进程中,同一进程支持多个component动态库加载。在dw启动时会相应启动stm_master、ScheduleManager进程,每个进程loadLite实例化相应的stm_client与实例化数(单)个app为runnables。
- 节点位于划分与同一loadLite进程中
根据graphlet数据流(data pipe)进入调用pass,若存在耗时异常的pass调用将堵塞整个进程。
- 节点位于划分于不同loadLite进程中
不同进程间的节点模块,调用顺序除了与graphlet数据流(data pipe)的依赖相关,还取决于资源的互斥(类似互斥锁)。通过stm_client的配置来设定各个
hyperepoch对Runnables中的Resources归属。stm的资源互斥、pass周期、data pipe依赖如下图所示:
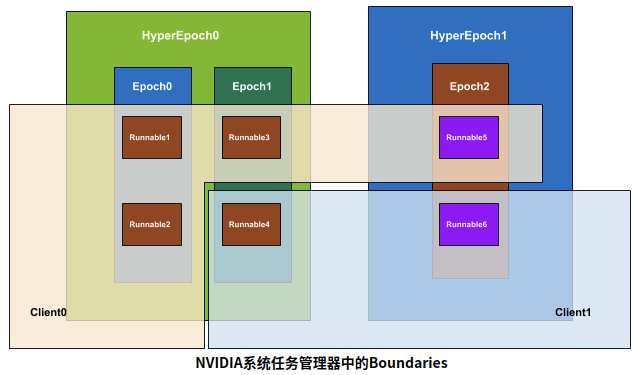
4. cgf节点收发数据的顺序以及并发关系
可认为不同process进程的每个(可能多个)节点构成的component动态库是独立的,进程间获取数据目前来看只要设定的定时器调用周期到达即进行处理。
5. 关于cgf节点超时处理后同步问题?
内部的周期调用应该是通过定时器实现的,如实验所示:period设定为33ms周期,当处理函数耗时1s时,该周期数据流动完毕将立刻进入新的周期处理函数,类似定时器超时后重新设置新的33ms定时器。
6. cgf的buffer的读写关系,是否有可能漏消息?
cgf内部维护一个收发数据的buffer,每次取数据getBuffer获取的是最老的数据。消息未全部处理时,isBufferAvailable一直返回ture。如果数据存储量过大,还是有丢失消息的可能。
cgf不支持在buffer多次写入,且不支持端口多写,修改fifo size 也不能写入多组数据无法验证该通道是否会存储旧消息。(注意发送消息时必须执行isBufferAvailable,不可直接sendbuffer数据)
7. cgf的循环依赖问题
对于数据datapipe出现环状时,descriptionScheduleYamlGenerator支持生成合理的yaml文件,里面的stm runnable将环状数据切割为链状供stm client遍历扫描。但是yaml中对于资源的循环依赖需要确保不能出现。