
背景
最近在做关于 容器资源控制,所以具体分析下lxc容器和Cgroups。
其实之前就已经做过 lxc容器 和 docker容器 的区别 内容探讨,不过是理论上的阐述,这里我再从core的具体实施来介绍下。
core内lxc容器的具体实施
首先,docker容器实现的两大元素是 namespace 和 Cgroups 做容器间属性隔离和资源控制。
顾名思义,lxc是 linux contain 的缩写,说明是由linux内核实现,做到资源的隔离这一容器的基础功能。而core 正是使用一系列linux内核实现 iproute2 封装的 netstat、虚拟网络设备命令构建的容器的namespace隔离和虚拟链路。
至于docker是用go实现了这些操作接口,并在不同系统上(例如windows的wsl)进行适配,所以core只能运行在linux发行版上。core并没有实现使用Cgroups进行相关资源控制操作,类似的docker自己用go实现了,当然 docker 的 namespace Cgroups底层还是linux内核提供支撑。
core里lxc容器和docker容器的具体实现区别:
core内的lxc通过 core/netns 文件夹内的 c语言实现的 vnode 来进行基础的容器创建(功能类似 ip netns 生成的挂载点一般是/tmp/pycore.XXX/nXXX 初始目录为 /tmp/pycore.XXXX/nXXX.conf),vcmd来与容器节点通信下发执行cmd。
Mount Namespace
隔离文件系统挂载点。值得注意的是:core中不会隔离全部路径,而是默认与主机共享。只有在节点的services配置了对应挂载点时,才会挂载节点独有目录。例如quagga服务中 为了隔离不同配置文件,core会挂载
/usr/local/etc/quagga文件夹。# 容器内查询到挂载目录 root@n1:/tmp/pycore.34513/n1.conf# findmnt | grep quagga │ └─/run/quagga /dev/sda4[/pycore.34513/n1.conf/var.run.quagga] ext4 rw,relatime └─/usr/local/etc/quagga /dev/sda4[/pycore.34513/n1.conf/usr.local.etc.quagga] ext4 rw,relatime # 宿主主机无法查询到挂载目录 lk233@vm-5gc:~$ findmnt | grep quagga而docker目录模式是隔离所有文件夹,通过UnionFS来实现目录下的全部隔离。
PID Namespace
隔离进程ID。值得注意的是:所有容器内进程都是vnode创建进程的fork子进程,docker容器也是类似的,所以 docker官方文档不推荐把容器当成虚拟机用部署多个进程,一个容器执行一个进程的思想。
关于pid的详细介绍可以看看这篇博客,总结就是:第0层的 pid命名空间是init进程所在的命名空间。如果一个进程所在的 pid命名空间 为 N,那么其在 0 ~ N 层pid命名空间 都有一个映射的唯一的pid号。也就是说 高层pid命名空间 的进程对 低层pid命名空间 的进程是可见的,但是 低层pid命名空间 的进程对 高层pid命名空间 的进程是不可见的。

# 宿主主机执行 lk233@vm-5gc:~/桌面/cgroups$ ps aux | grep zebra quagga 12397 0.0 0.0 27680 3160 ? Ss 11:32 0:00 /usr/sbin/zebra -d quagga 12450 0.0 0.0 27680 3116 ? Ss 11:32 0:00 /usr/sbin/zebra -d # 容器内执行 root@n1:/tmp/pycore.36535/n1.conf# ps aux | grep zebra quagga 29 0.0 0.0 27680 3160 ? Ss 11:32 0:00 /usr/sbin/zebra -d网络链路的区别
docker网络比较简单,有四种网络模式:
网络模式 配置 说明 bridge模式 | –net=bridge | (默认模式) 此模式会为每一个容器隔离空间后,创建veth pair一端放入容器设置IP等,另一端连接到一个docker0虚拟网桥,通过docker0网桥以及Iptables nat表配置与宿主机端口映射,相互通信。 | host模式 | –net=host | 容器和宿主机共享Network namespace,即不隔离网络空间。 | container模式 –net=容器名或id 容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。 none模式 –net=none 该模式关闭了容器的网络功能,即与主机网络空间隔离开 而core内的lxc容器默认是none模式,然后自己根据拓扑创建链路,使用veth pair、 tap/tun、bridge等网络虚拟设备实现。下图是一个基础的点对点链路构建。
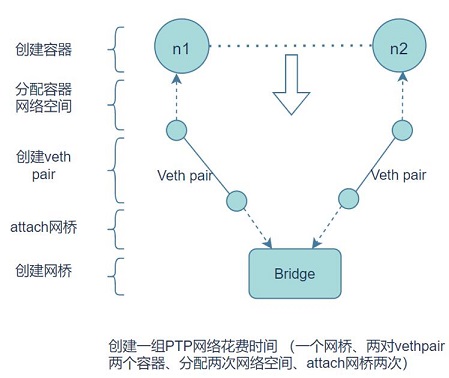
IPC Namespace 隔离
区分 System V IPC 和 POSIX 消息队列。
Network Namespace
隔离网络设备资源,例如端口、ip地址等。
UTS Namespace
隔离主机名和域名。
User Namespace
隔离用户和用户组。
关于Cgroups的使用
参考这篇知乎博客的介绍,复现了下对core容器的cpu、内存控制。
相关概念介绍
Cgroups全称Control Groups,是Linux内核提供的物理资源隔离机制,通过这种机制,可以实现对Linux进程或者进程组的资源限制、隔离和统计功能。
比如可以通过cgroup限制特定进程的资源使用,比如使用特定数目的cpu核数和特定大小的内存,如果资源超限的情况下,会被暂停或者杀掉。
Cgroup是于2.6内核由Google公司主导引入的,它是Linux内核实现资源虚拟化的技术基石,LXC(Linux Containers)和docker容器所用到的资源隔离技术,正是Cgroup。
子系统(subsystem): 一个子系统其实就是一种资源的控制器,在linux上会挂载到例如目录
/sys/fs/cgroup/cpu/lk233_cpu_test上,查询对应文件就可以看到配置和当前资源的参数,比如memory子系统可以控制进程内存的使用。子系统需要加入到某个层级,然后该层级的所有控制组,均受到这个子系统的控制。任务(task): 在cgroup中,任务就是一个进程。控制组(control group): cgroup的资源控制是以控制组的方式实现,控制组指明了资源的配额限制。进程可以加入到某个控制组,也可以迁移到另一个控制组。查询对应
cat /sys/fs/cgroup/cpu/lk233_cpu_test/tasks即可知道该控制组包含的参数。层级(hierarchy): 控制组有层级关系,类似树的结构,子节点的控制组继承父控制组的属性(资源配额、限制等)。父子集 有关联 子资源会统计到父level 强制修改父的小于子限制,对应的父或子会改为默认值(无限制)。使得层级从上往下 依照最小的资源控制组来算。如下所示,limit_50控制组就是lk233_cpu_test控制组的子集合,其受到父控制组的限制。
lk233@vm-5gc:/sys/fs/cgroup/cpu/lk233_cpu_test$ tree
.
├── cgroup.clone_children
├── cgroup.procs
├── cpuacct.XX
├── cpu.XX
├── limit_50
│ ├── cgroup.clone_children
| ├── cpuacct.XX
| ├── cpu.XX #类似父文件夹内容
│ └── tasks
├── notify_on_release
└── tasks
实际测试
主要分析下 cpu memory相关的参数:
cpu文件夹内容:
lk233@vm-5gc:/sys/fs/cgroup/cpu/lk233_cpu_test/limit_50$ tree
.
├── cgroup.clone_children
├── cgroup.procs
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── cpu.uclamp.max
├── cpu.uclamp.min
├── notify_on_release
└── tasks
cfs是Completely Fair Scheduler的缩写,代表完全公平调度,rt是RealTime的缩写,它是实时调度。这里使用的是cfs调度机制。
具体介绍,大概分为两类: cpu.XX : 用来限制cgroup的CPU使用率 cpuacct.XX : 用来统计cgroup的CPU的使用率 可以利用cpuacct的值来做cpu性能监控: cpuacct.usage: 该cgroup中所有任务总共使用的CPU时间(ns纳秒) cpuacct.stat: 该cgroup中所有任务总共使用的CPU时间,区分user和system时间。 cpuacct.usage_percpu: 该cgroup中所有任务使用各个CPU核数的时间。 计算cpu利用率示例:
# 1. 获取当前时间(纳秒)
tstart=$(date +%s%N)
# 2. 获取cpuacct.usage
cstart=$(cat /xxx/cpuacct.usage)
# 3. 间隔5s统计一下
sleep 5
# 4. 再次采点
tstop=$(date +%s%N)
cstop=$(cat /xxx/cpuacct.usage)
# 5. 计算利用率
($cstop - $cstart) / ($tstop - $tstart) * 100
memory文件夹内容:
lk233@vm-5gc:/sys/fs/cgroup/memory/lk233_cpu_test/limit_50$ tree
.
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── memory.failcnt
├── memory.force_empty
├── memory.kmem.failcnt
├── memory.kmem.limit_in_bytes
├── memory.kmem.max_usage_in_bytes
├── memory.kmem.slabinfo
├── memory.kmem.tcp.failcnt
├── memory.kmem.tcp.limit_in_bytes
├── memory.kmem.tcp.max_usage_in_bytes
├── memory.kmem.tcp.usage_in_bytes
├── memory.kmem.usage_in_bytes
├── memory.limit_in_bytes
├── memory.max_usage_in_bytes
├── memory.move_charge_at_immigrate
├── memory.numa_stat
├── memory.oom_control
├── memory.pressure_level
├── memory.soft_limit_in_bytes
├── memory.stat
├── memory.swappiness
├── memory.usage_in_bytes
├── memory.use_hierarchy
├── notify_on_release
└── tasks
内存的具体参数就不赘述 具体可以看知乎或google
Cgroups资源操作
原始的方法,例如我这里限制cpu占用为50%,可以如下执行
sudo mkdir /sys/fs/cgroup/cpu/lk233_cpu_test/limit_50/
# 创建好目录后就会自动挂载并生成对应控制组文件
sudo echo '100000' > test_cpu/cpu.cfs_period_us
sudo echo '50000' > test_cpu/cpu.cfs_quota_us
sudo echo 进程pid >> /sys/fs/cgroup/cpu/lk233_cpu_test/limit_50/tasks
当然不必如此原始操作,可以如下sudo apt install cgroup-bin使用一些自动创建的工具,例如上面的lk233_cpu_test 是一个管理组,直接用 cgcreate 做也可。(创建的名字随意,这里内存控制组无意的命名为lk233_cpu_test了😂)
# 创建控制组
sudo cgcreate -t $USER:$USER -a $USER:$USER -g cpu:lk233_cpu_test/limit_50
# 用来配置时间周期长度,单位是us,取值范围1000~1000000:1ms ~ 1s 系统总时间片为 核心数 * cpu.cfs_period_us
cgset -r cpu.cfs_period_us=100000 lk233_cpu_test/limit_50
# 设置可用CPU时间数,单位us,最小值为1000
cgset -r cpu.cfs_quota_us=50000 lk233_cpu_test/limit_50
# 删除控制组
sudo cgdelete cpu:lk233_cpu_test/limit_50
# 读取配置组参数
cgget -g cpu:lk233_cpu_test/limit_50
# 同理内存设置上限为100MB(参数单位为字节)的操作类似 具体如下所示
sudo cgcreate -t $USER:$USER -a $USER:$USER -g memory:lk233_cpu_test/limit_50
cgset -r memory.limit_in_bytes=104857600 lk233_cpu_test/limit_50
执行程序
由于代码只考虑了线程的情况,lxc容器内进程是fork形式,所以这里代码里添加了一个fork的函数。编译该程序,记得添加动态库参数 g++ -o cpu_test cpu_test.cpp --std=c++11 -lpthread
void test_cpu() {
pid_t tid = syscall(SYS_gettid);
printf("cpu theard id is %d\n", tid);
int total = 0;
while (1) {
++total;
}
}
void test_mem() {
pid_t tid = syscall(SYS_gettid);
printf("mem theard id is %d\n", tid);
int step = 10;
int size = 20 * 1024 * 1024; // 20Mb
for (int i = 0; i < step; ++i) {
char* tmp = new char[size];
if (tmp == nullptr) {
printf("new error, %d MB memory is used\n", i*20);
return;
}
printf("tmp address is %p\n", tmp);
memset(tmp, i, size);
sleep(1);
}
printf("thread: 200 MB memory is used\n");
}
int main(int argc, char** argv) { // 跑cpu、内存线程,并且fork内存进程
pid_t tid = syscall(SYS_gettid);
printf("father theard id is %d\n", tid);
std::thread t1(test_cpu);
std::thread t2(test_mem);
pid_t pid = fork();
if (pid < 0) {
printf("error\n");
return 1;
}
else if (pid == 0) {
printf("fork success,this is son process: ");
test_cpu();
}
else {
t1.join();
t2.join();
}
return 0;
}
int main1(int argc, char** argv) { // 跑两个cpu线程
pid_t tid = syscall(SYS_gettid);
printf("father theard id is %d\n", tid);
std::thread t1(test_cpu);
std::thread t2(test_cpu);
t1.join();
t2.join();
return 0;
}
结果分析
我们自己建的控制组重启后会丢失 可以类似docker的service重启后自动创建对应控制组
cpu相关的控制测试
cpu_test 子线程test_cpu函数循环+1会占用所有cpu时间片,容易显示观察到。首先注释test_mem内存相关的代码。通过 cgexec 实现执行该进程直接加入控制组
cgexec -g cpu:lk233_cpu_test/limit_50 ./cpu_test未设置控制组(主函数执行main1情况):
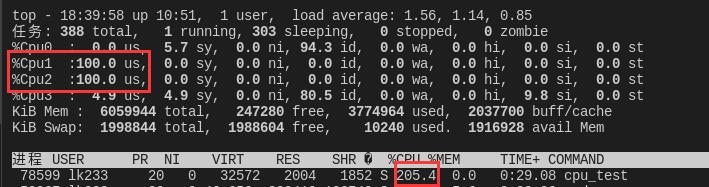
由于我的linux主机是双核的,所以top命令查出来的cpu占用达到200%。(两个cpu核跑满)
设置控制组后
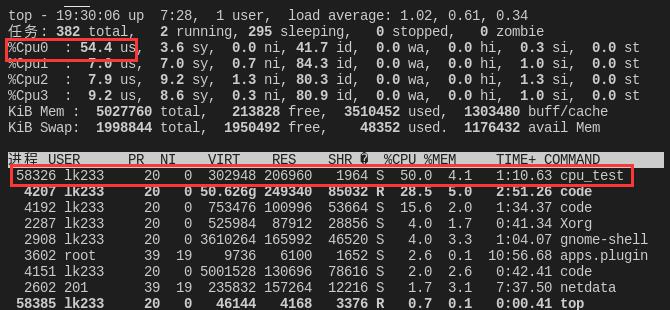
可以知道控制组控制cpu时间是统计加入到改组的全部进程、线程并控制。所以前面设置时间片为50000,哪怕是两个线程也只占了50%。这里 总时间片为 cpu.cfs_period_us * 4 = 400000 cpu最大跑到400%。
查询task
cat /sys/fs/cgroup/cpu/lk233_cpu_test/limit_50/tasks可以看到有多少进程加入该控制组。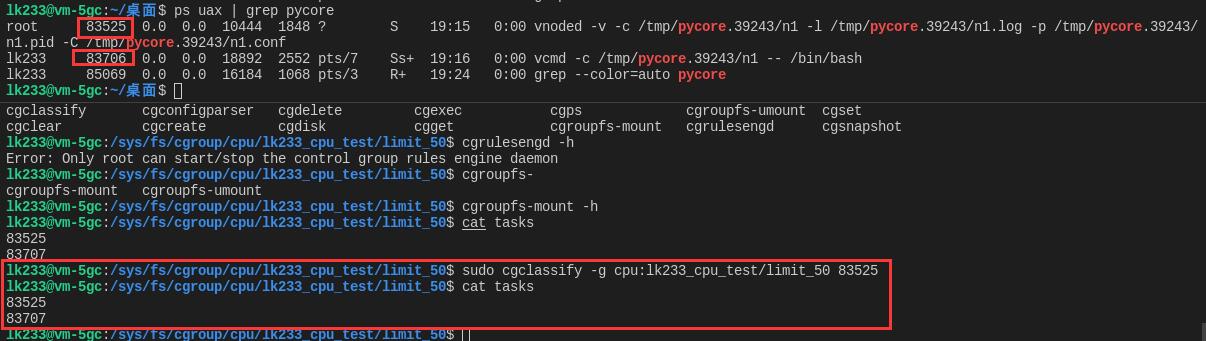
但是这里我看到了两个pid,可是按照我们平时的学习,一个进程的多个线程公用一个pid。所以我试着使用 attach 命令将运行的进程加入控制组的task看看是否会变成两个。
将pid绑入对应目录task,
cgclassify -g cpu:lk233_cpu_test/limit_50 线程tid list想要删除控制可以留一个没有配置的控制组,将该进程移植过去。结果查询task发现只有一个pid,但是cpu资源并没有受到控制。说明派生的线程没有加入控制组。一番查询后,stackflow上的这个回答很不错。
注意这里的多线程 pid 用户态子线程pid(线程组tgid)的确相同 但是内核态不同(叫做 thread id, tid) 所以添加task这里只限制父线程无效
/* 用户态看的是 tgid 内核态看的是tid **USER VIEW** <-- PID 43 -->|<----------------- PID 42 -----------------> | | | +---------+ | | | process | | | __| tid=42 |__ | __(fork)__/ | tgid=42 | \__(new thread)_ / | +---------+ | \ +---------+ | | +---------+ | process | | | | process | | tid=43 | | | | tid=44 | | tgid=43 | | | | tgid=42 | +---------+ | | +---------+ | | <-- PID 43 -->|<--------- PID 42 --------->|<--- PID 44 ---> **KERNEL VIEW** # 命令行下查询 可以看到子线程的tid pstree -p pid cpu_test(79426)─┬─{cpu_test}(79427) └─{cpu_test}(79428) # 程序中 tgid: getpid() tid: syscall(SYS_gettid) 线程id: pthread_self() # 线程id 是 pthread 库维持的, 故此“ID”的作用域是进程级而非系统级 # 所以前面的cpp代码我直接添加了打印tid的语句。我在此之后继续测试,最后得出结论:添加入控制组的进程,无论fork还是子线程都会自动加入控制组,在此之前的不会加入控制组。
下面是我将core里的lxc容器绑定到控制组的结果
内存相关的控制测试
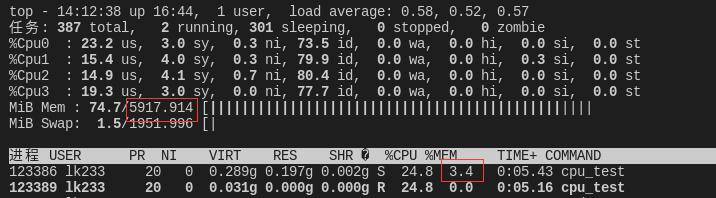
在top终端界面下输入h查看帮助。按E切换内存单位,1开启cpu核心查看,m查看内存详细使用。
正常启动时,可以看到内存占用为 5917.914 * 3.4% = 201 mb
内存控制组类似cpu控制组做法,这里进程既加入cpu控制组也加入内存控制组。
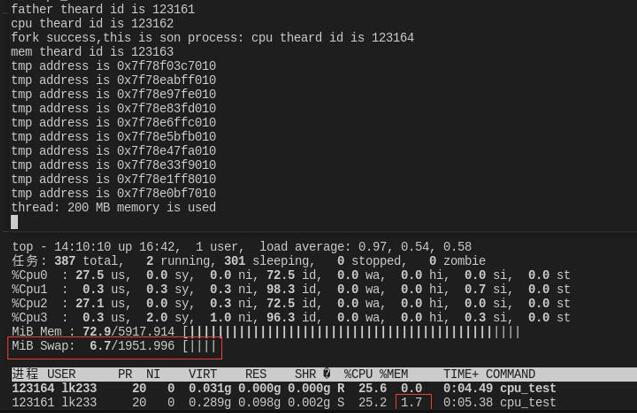
cgexec -g cpu:lk233_cpu_test/limit_50 -g memory:lk233_cpu_test/limit_50 ./cpu_test结果创建内存案例会创建200Mb,但是我限制了100mb会报错之类的,但是一切正常,只是执行后面申请100mb时打印语句速度变慢。
仔细观察后发现,原来内存不够他去申请虚拟内存去了,什么精打细算够🙄
我们继续,看看设置不用虚拟内存 内存不够后会发生什么。
cgset -r memory.swappiness=0 lk233_cpu_test/limit_50结果就是终端直接打印 已杀死,好家伙!然后看了这篇文章可以配置 oom_kill_disable 在控制组内进程申请内存不足时等待而不是直接杀死
cgset -r memory.oom_control=1 lk233_cpu_test/limit_50
总结
core内的lxc容器是可以直接使用 cgclassify 绑定控制组的,之后可以针对不同需求提前自动化创建控制组。也可以在界面添加选项接口,使用cpuacct.usage等参数计算cpu占用,做到实时创建控制组并实现容器资源的控制与监听。