
之前安装docker时候惊讶其居然有windows版本的安装包,心想 docker 不是靠linux内核实现的资源控制空间隔离么,怎么会有windows版本,看了下安装方法才了解到 微软内置了linux内核的子系统,即 wsl (Windows Subsystem for Linux)。
可以在win系统上不用虚拟机的方式原生执行 linux ,没有虚拟机那些其他开销,这也太牛了直接开整,试试wsl好不好用,也玩下windows版的docker。
配置 wsl
在 powershell 下:
wsl --install # 配置环境
wsl --list --online # 只有内核 还需要在该列表中选择镜像启动
wsl --install -d <DistroName>
WSL 2 使用最新、最强大的虚拟化技术在轻量级实用工具虚拟机 (VM) 中运行 Linux 内核。 所以先升级对应wsl内核版本(docker只能运行在wsl2上)适用于 x64 计算机的 WSL2 Linux 内核更新包
wsl # 开启并进入默认系统 后加命令会在分发系统内执行该命令
wsl -d Ubuntu -u root # 进入指定版本 指定用户
wsl --export <Distribution Name> <FileName> # 系统导出
wsl --import <Distribution Name> <InstallLocation> <FileName> # 系统导入
wsl --unregister <DistributionName> # 卸载系统
wsl -l -v # 查看全部系统的wsl版本 和状态
wsl --terminate, -t <distro name> # 关闭该系统 --shutdown 关闭全部系统
wsl --set-default-version <Version> # 设置默认 WSL 版本
wsl --distribution <Distribution Name> --user <User Name> # 以特定用户 运行 linux发行版
导入系统的发行包没法像 ubuntu2004.exe config --default-user new_user_name 配置默认登录用户,进入发行系统,添加或修改 /etc/wsl.conf 停止wsl系统重新进入即可生效。
YourUserName=lk233
sudo echo -e "[user] \ndefault = $YourUserName" > /etc/wsl.conf
若是不对wsl资源进行限制,其vmmem进程会逐渐吃光物理机内存,参考该WSL 中的高级设置配置 | Microsoft Docs 进行限定wsl系统性能。 Linux内核中有一个参数/proc/sys/vm/drop_caches,是可以用来手动释放Linux中的cache缓存,如果发现wsl2的cache过大影响到宿主机正常运行了,可以手动执行以下命令来释放cache:
echo 3 > /proc/sys/vm/drop_caches
开发环境
配置用户后 拿来跑数据库 docker Linux gui应用(需要win11) 前端框架 甚至机器学习 的python 项目都可以。设置 WSL 开发环境 | Microsoft Docs
使用windows的资源管理器查看wsl系统,路径为 \\wsl$\系统名 其默认的真实路径为 C:\Users\LAB\AppData\Local\Packages\Project$ 路径后缀肯定是不同机器不一样的我这里Project$ = CanonicalGroupLimited.Ubuntu20.04onWindows_79rhkp1fndgsc。在linux内该路径为 /mnt/c 对应 windows中的c盘,使用 explorer.exe . 来在资源管理器中查看。像docker这类应用考虑到io性能,最好使用 linux内的路径例如 ~/my-project 而不是 /mnt/c/users 这样的挂载路径。
原生的 powersehll 不太好用,也懒得整个windows终端。接下来使用vscode来优雅的体验wsl吧。wsl分发系统 通过虚拟网卡vEthernet (WSL) 与物理主机连接,就像远程登录其它linux主机一样,wsl作为服务器主机,vscode作为客户端显示。所以当本地vscode 升级时,远端 / wsl 的 code server 也会升级。
把 集成wsl2 的 docker 装起来,WSL 上的 Docker 容器入门 | Microsoft Docs 配置好后wsl就可以使用 docker了。
由于win系统都是通过调用linux内核实现docker功能,整个 docker daemon 还是由docker-desktop控制的,所以只在本地主机上的 vscode 配置 docker 和 remote-docker 插件进行全局管理即可。可以看到 wsl 多了 两个发行版 docker-desktop-data docker-desktop 对应路径为 C:\Users\user\AppData\Local\Docker\wsl。后面C盘占用太高可以尝试迁移: WSL2 迁移 Docker 镜像存储位置
项目执行
一切就绪,试试跑这个 爬虫监视项目。其他 mangodb grafana influxdb 等环境 跑个docker容器即可。该项目使用selenium 爬取豆瓣关键词相关电影信息存入 mongodb中,使用 时序数据库 InfluxDB 来记录将数据抓取的变化情况,使用 Grafana 展示。
注意 redis 配置文件不要开 daemonize yes,类似的 monggo也不要开 fork之类的后台执行。
使用 docker-compose 部署数据库容器: docker-compose up -d 不使用 -f 指定默认使用当前目录的docker-compose.yml
docker-compose
# Use root/example as user/password credentials
version: '3.1'
services:
mongo:
image: mongo
restart: always
container_name: some-mongo
ports:
- 27017:27017
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
volumes:
- ~/MyCustom/mongo/daemon_config:/etc/mongo
- ~/MyCustom/mongo/mong_data_conf:/data/configdb
- mong_data:/data/db
command: --config /etc/mongo/mongod.conf
mongo-express:
image: mongo-express
container_name: mongo-express
depends_on:
- mongo
restart: always
ports:
- 8081:8081
environment:
ME_CONFIG_MONGODB_AUTH_USERNAME: root
ME_CONFIG_MONGODB_AUTH_PASSWORD: example
ME_CONFIG_BASICAUTH_USERNAME: root # 管理界面 express 的账号 密码
ME_CONFIG_BASICAUTH_PASSWORD: lk233pass
ME_CONFIG_MONGODB_URL: mongodb://root:example@mongo:27017/
VCAP_APP_HOST: 0.0.0.0
VCAP_APP_PORT: 8081
# 配置参数 https://grafana.com/docs/grafana/latest/administration/configure-docker/ 默认账户密码 admin@admin
grafana:
image: grafana/grafana
container_name: grafana
ports:
- 3000:3000
environment:
GF_DEFAULT_INSTANCE_NAME: my-instance
GF_SECURITY_ADMIN_USER: root
GF_AUTH_GOOGLE_CLIENT_SECRET: example
GF_PLUGIN_GRAFANA_IMAGE_RENDERER_RENDERING_IGNORE_HTTPS_ERRORS: true
# influxdb docker 配置 https://hub.docker.com/_/influxdb
influxdb:
image: influxdb
container_name: influxdb
ports:
- 8086:8086
volumes:
- influxdb_data:/var/lib/influxdb2
- ~/MyCustom/influx_db/config:/data/db
environment:
# DOCKER_INFLUXDB_INIT_MODE: setup upgrade
DOCKER_INFLUXDB_INIT_USERNAME: root
DOCKER_INFLUXDB_INIT_PASSWORD: example
DOCKER_INFLUXDB_INIT_ORG: my_org
DOCKER_INFLUXDB_INIT_BUCKET: my_bucket
volumes:
mong_data:
redis_data:
influxdb_data:
mong_data_conf:
由于wsl里没有浏览器,所以这个抓取的脚本改为用 edge 的在windows上执行。然后脚本有些函数被弃用了,修改后的版本。如果 msedgedriver 不在path环境下,需要设定 路径。
爬虫代码
# -*- coding:utf-8 -*-
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
from selenium.common.exceptions import TimeoutException
from msedge.selenium_tools import Edge, EdgeOptions
from lxml import etree
import pymongo
import datetime
MONGO_URL = 'mongodb://root:example@172.18.96.216:27017/'
MONGO_DB = 'douband_movices'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
MONGO_TABLE = "movie_info"
key_word = input("请输入需要爬取的关键词: ")
edge_options = EdgeOptions()
edge_options.use_chromium = True
edge_options.add_argument("inprivate")
browser = Edge(executable_path = "E:\\Github_code\\Tools\\spider_douban_selenium_mongodb\\msedgedriver.exe", options=edge_options)
wait = WebDriverWait(browser,10)
browser.get('https://movie.douban.com/')
def search():
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#inp-query'))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#db-nav-movie > div.nav-wrap > div > div.nav-search > form > fieldset > div.inp-btn > input[type="submit"]'))
)
input.send_keys('{}'.format(key_word))
submit.click()
print('正在加载')
active = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'a.num.activate.thispage'))
)
print('加载第【{}】页成功'.format(active.text))
get_movies()
except TimeoutException:
print('等待超时,重新搜索...')
return search()
def next_page():
try:
next_page_submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'a.next'))
)
next_page_submit.click()
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'a.num.activate.thispage'))
)
print('成功加载该页数据...')
get_movies()
print('--------------加载完成,并打印成功,开始加载下一页------------')
time.sleep(3)
next_page()
except TimeoutException:
print('加载超时,重新加载...')
return next_page()
def get_movies():
try:
print('正在解析...')
page = browser.page_source.encode('utf-8')
selector = etree.HTML(page)
print('开始打印输出电影信息...')
items = selector.xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]')
for item in items:
names = item.xpath('div/div/div/div[1]/a/text()')
urls = item.xpath('div/div/div/div[1]/a/@href')
ratings = item.xpath('div/div/div/div[2]/span[2]/text()')
durations = re.findall(r'\d\d+',str(item.xpath('div/div/div/div[3]/text()')))
actors = item.xpath('div/div/div/div[4]/text()')
for name,url,rating,duration,actor in zip(names,urls,ratings,durations,actors): # 打包为元组的列表
movie_info = {}
movie_info['name'] = name
movie_info['url'] = url
if rating == '(尚未上映)' or '(暂无评分)':
movie_info['rating'] = None
else:
movie_info['rating'] = float(rating)
movie_info['duration'] = int(duration)
movie_info['actors'] = actor
movie_info['key_word'] = key_word
print(movie_info)
save_to_mongo(movie_info)
except Exception as e:
print(e)
time.sleep(3)
return get_movies()
def save_to_mongo(result):
try:
# if db[MONGO_TABLE].insert_one(result):
if db.get_collection(MONGO_TABLE).insert_one(result): # get 函数没有该表便会创建一个
print('成功存储到MONGODB')
except Exception as e:
raise e
def main():
start_time = datetime.datetime.now()
# global MONGO_TABLE # 定义写入的表为时间戳
# MONGO_TABLE = start_time.strftime("%Y-%m-%d %H:%M:%S")
try:
db_list = client.list_database_names() # db.list_collection_names() 是该数据库的全部数据集
print(f"全部数据库为: {db_list}")
if MONGO_DB in db_list :
print("数据库存在")
search()
next_page()
else:
print(f"{MONGO_DB} 不存在, 连接不可用")
except Exception as e:
raise e
finally:
browser.close()
end_time = datetime.datetime.now()
print('*'*100)
print('共计用时:', end_time - start_time)
total_nums = db[MONGO_TABLE].count_documents({})
print('共计获取数据:',total_nums,' 条')
print('*'*100)
if __name__ == '__main__':
main()
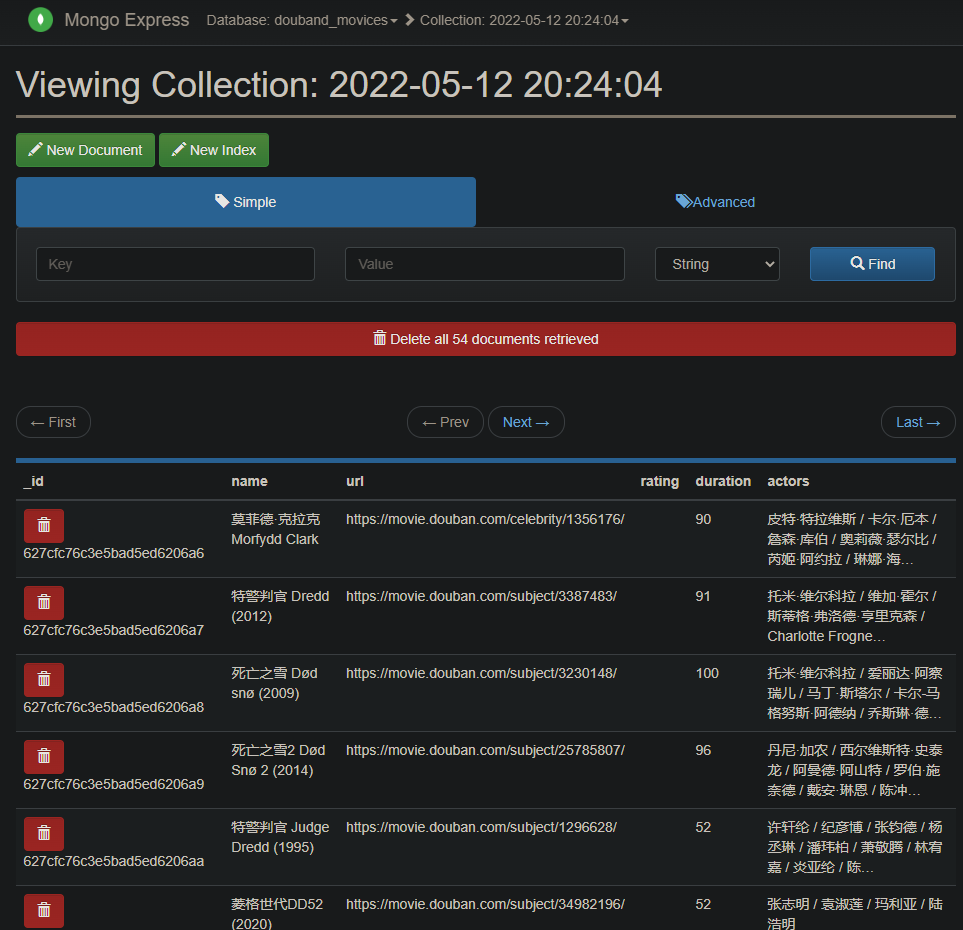
验证 mongodb 的数据可以使用 mongo-express 直接访问 wsl_ip:8081 例如 172.18.96.216:8081 即可图形化界面查看筛选数据库内容。
influxdb采集脚本
InfluxDB 的版本变化,原文章的脚本不在适用,启用influx容器后 访问 8086 端口,进入后查看 data 页 的Client L ibraries 查看编写例程。
改写后:
from datetime import datetime
from influxdb_client import InfluxDBClient, Point, WritePrecision
from influxdb_client.client.write_api import SYNCHRONOUS
import pymongo, time
# You can generate an API token from the "API Tokens Tab" in the UI
token = "UNX9i2BpV_VTWyccXomQ6F026rg6j_nUeXtheR4THu8WoWmky09Fgw2WBJAltHL0sQadeDaSb2OGE-J0B7-2vg=="
org = "CQUPT"
bucket = "douban"
MONGO_URL = 'mongodb://root:example@172.18.96.216:27017/'
MONGO_DB = 'douband_movices'
mongodb = pymongo.MongoClient(MONGO_URL).get_database(MONGO_DB) # 连接 MongoDB 数据库
client = InfluxDBClient(url="http://172.18.96.216:8086", token=token, org=org) # 连接 influxDB 数据库
write_api = client.write_api(write_options=SYNCHRONOUS)
interval = 8
def main() :
last_size, last_count = {}, {}
for dbname in mongodb.list_collection_names():
last_size[dbname], last_count[dbname] = 0.0, 0
while True:
for dbname in mongodb.list_collection_names():
# db = mongodb.get_collection(dbname)
dbstat = mongodb.command("collstats", dbname)
now_size = round(float(dbstat["size"] / 1024 / 1024), 2)
now_count = dbstat["count"]
# 得到数据 增长量
increase_amount = now_size - last_size[dbname]
increase_collection_size = now_count - last_count[dbname]
point = Point("crawler") \
.tag("db_name", dbname) \
.field("count", now_count) \
.field("increase_count", increase_amount) \
.field("size", now_size) \
.field("increase_size", increase_collection_size) \
.time(datetime.utcnow(), WritePrecision.NS)
write_api.write(bucket, org, point)
print('成功写入influxdb 数据: ', point)
last_size[dbname], last_count[dbname] = now_size, now_count
time.sleep(interval)
if __name__ == '__main__':
main()
先试试 能够否 如图 将 Buckets 的数据争取抓出来,筛选好信息 submit 看见有数据导入即可验证 influx 脚本正常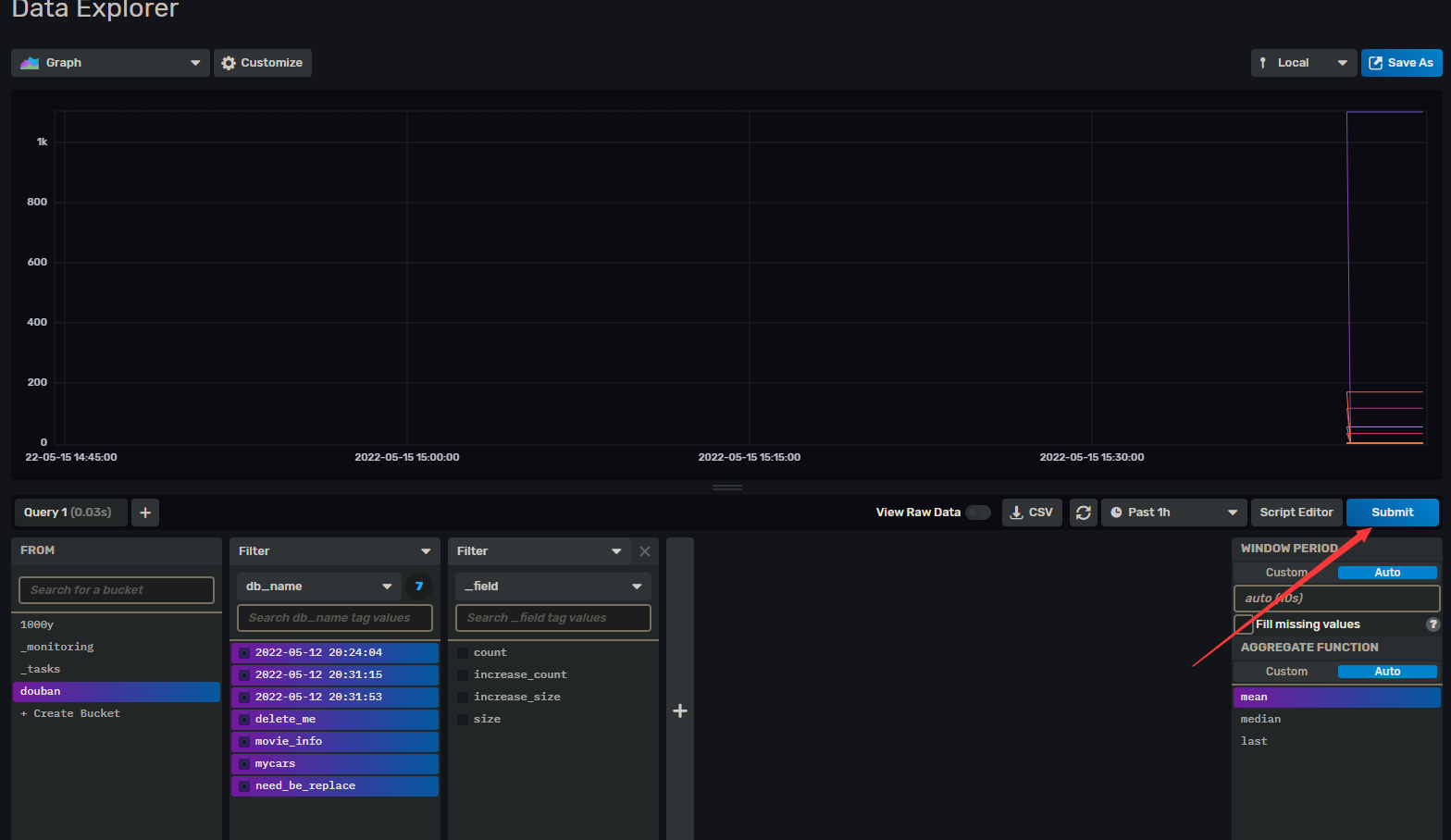
Grafans 配置
最后配置 Grafans,进入 3000 端口 admin账号 密码admin 创建初始账号。新版的 Grafans 已经有直接支持 mongodb 了,绝了 绕一大圈😫。还是先像文章一样配置数据库吧。
介绍下怎么装插件:
# 进入容器终端
docker exec -it grafana bash
grafana-cli plugins list-remote
grafana-cli plugins install grafana-mongodb-datasource
# 之后重启容器即可生效
docker container restart grafana
图形界面 Server Admin 的 plugins 选项下装插件更方便,而且很奇怪无法在 Configuration / Data sources 下 使用 Add data source 按钮添加该数据库,只能在 Configuration 的 plugins 或 Server Admin 的 plugins 下添加。
配置好后 弹窗 Enterprise License Error 发现是 需要企业版才能用。放弃!
老老实实配 influx 吧,2.0以上版本 Query Language 使用 Flux,这里的ip要注意,我之前搭建的环境都是通过 wsl 的ip 172.18.96.216 来进行通信的,而此处是 grafana 容器访问 influx 容器,所以跨网段会找不到路由,排错了半天在 日志里才发现端倪,进 ifluxdb 容器 内执行 ip link addr show 获取ip为 172.18.0.4,连接配置 url 设置为其网关或网卡ip,InfluxDB Details 里的 token 为 上述代码用到的 api token。
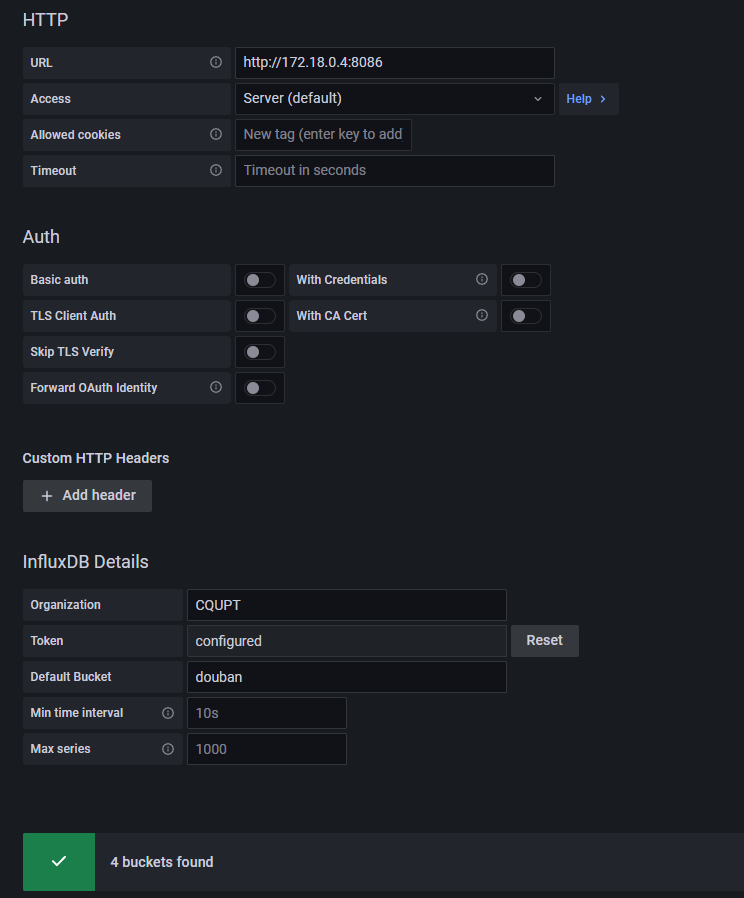
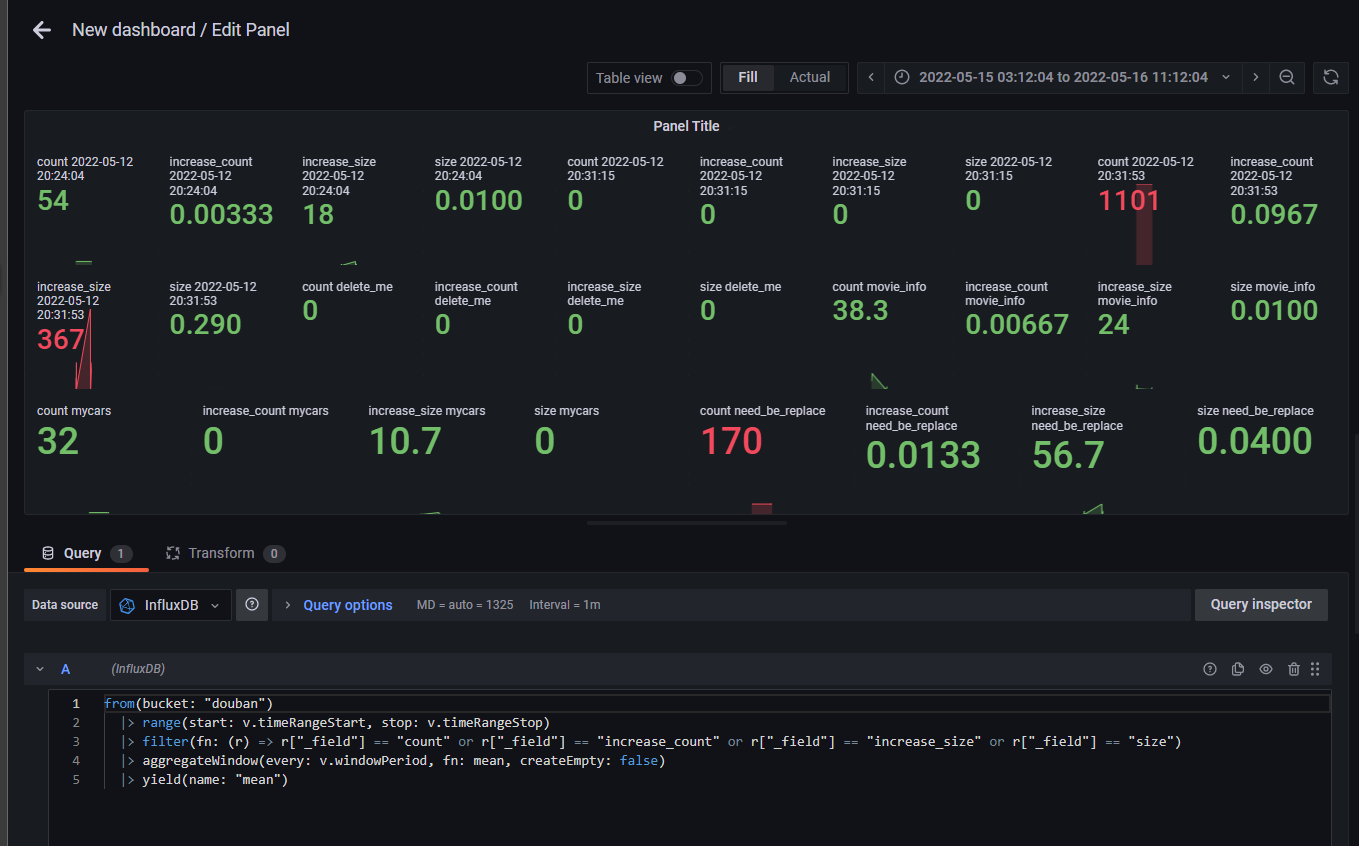
最后在 dashboard 添加一个新的 panel, query 里选择 influxDB 使用 sample Query 快速填入一些简单的案例。或者直接在 ifluxdb的界面 Data Explorer中进行元素筛选,然后点击 Scipt Editor 复制其查询语句 Grafans 到 panel。设定完成后 Query inspector 生成对应图像示例。
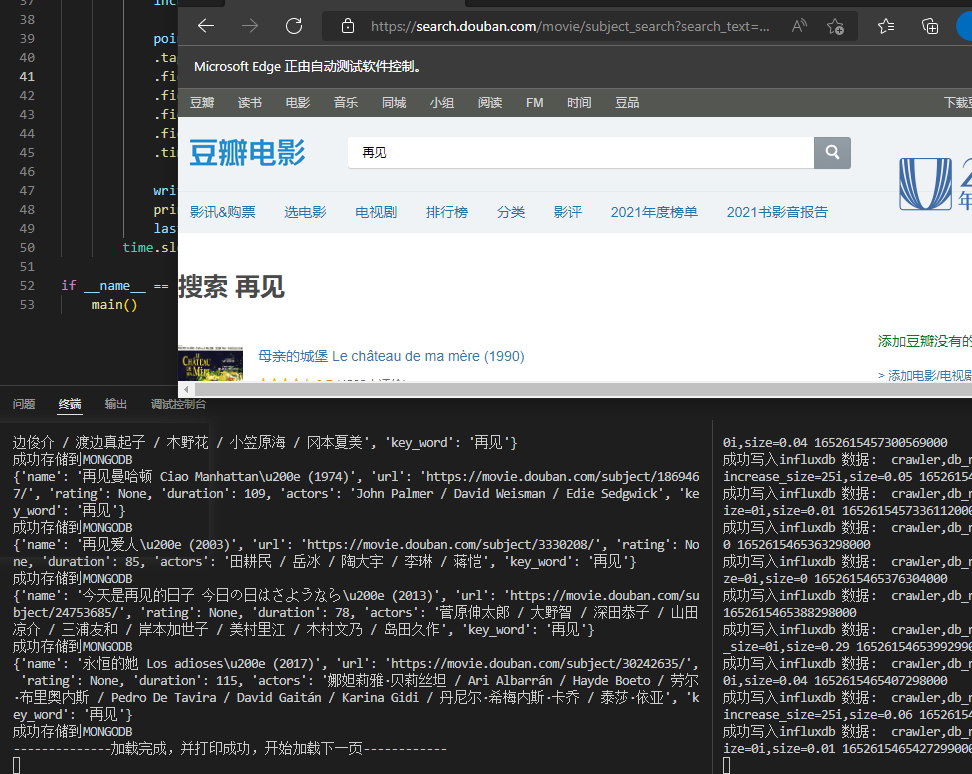
然后 开始爬数据 看看渲染效果
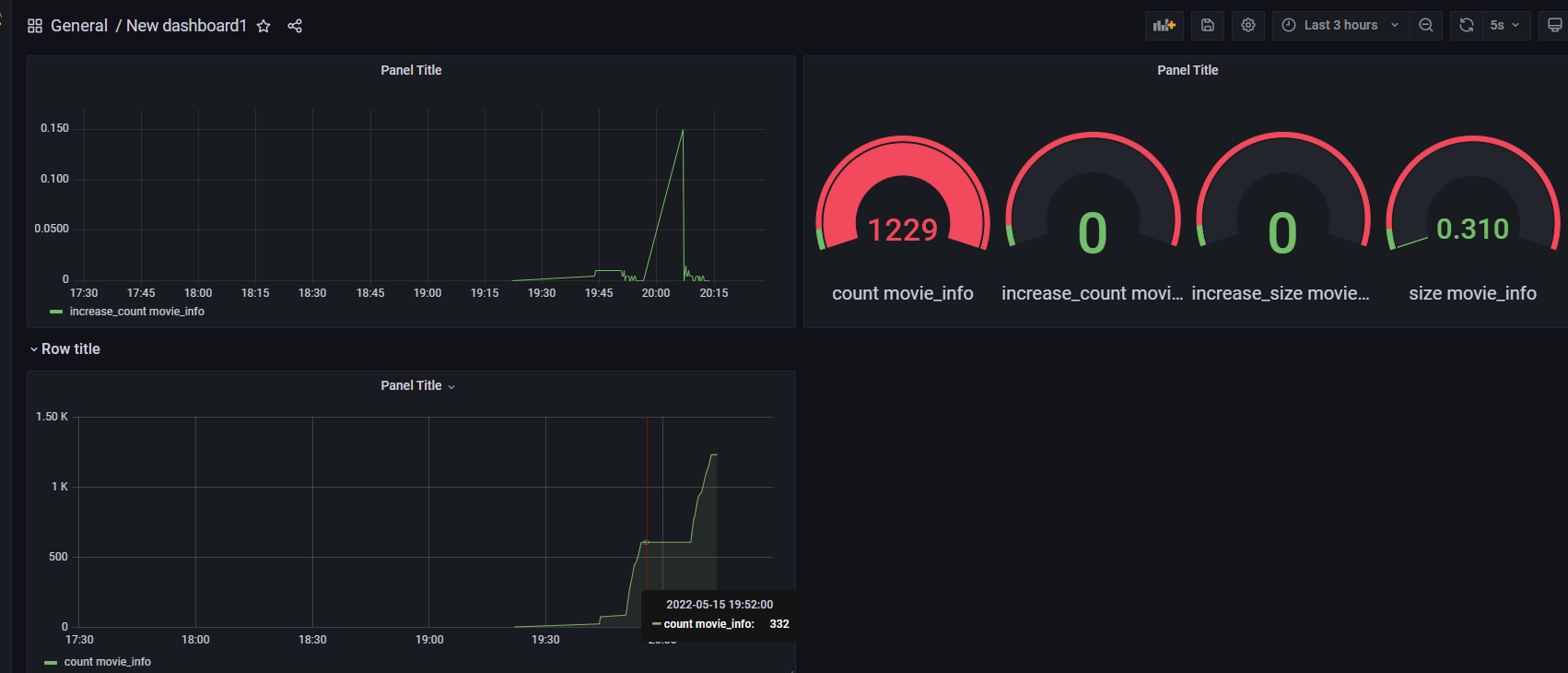
可以看看其他写的比较好的 Grafana 教程 数据导出的插件也有很多方便的实现,例如 Prometheus 搭配各类 Exporter 统计数据,Prometheus 的显示可以使用 Grafana 现有的仪表盘导入prometheus的数据能做到许多监控效果例如mysql 主机运行状态等监控参数。(在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。)
Grafana 在很多地方都有应用,也许以后还会有用到的时候,有机会再分享关于它的用法的。
属于是跑题跑偏了😂,最开始只想整个wsl,结果搞到容器部署 数据库 和资源监控了。